Jan 20, 2026
How to Compare AI Models: A Founder's Guide
Struggling to compare AI models? Use this founder's framework to evaluate cost, speed, and accuracy, helping you make smarter, more profitable AI decisions.

When I started my AI company, I thought the goal was to find the single "best" AI model. That mindset was a mistake, and it cost me time and money. The real breakthrough came when I stopped searching for one all-powerful tool and started building a strategic, multi-model approach. This isn't just about technology; it's about matching the right tool to the right job to save serious cash and reduce business risk. This guide shares the practical, first-person lessons I learned along the way.
Why We Must Compare AI Models Before Committing
As a founder, I learned a lesson that has saved us thousands of dollars, and it's one I wish I'd known sooner: committing to a single AI model too early is a costly mistake. The initial thrill of plugging in a powerful tool like GPT-4o often masks the creeping costs and performance bottlenecks that inevitably show up down the line. I'm telling you this not as a theory, but as a hard-won piece of experience that directly impacts your cash flow.
When we first built our company, the instinct was to just find the "best" model and use it for everything. The simplicity was appealing. But I quickly realized that's like using a sledgehammer for every task in a workshop. Sure, it’s powerful, but it’s also wildly inefficient and expensive most of the time.
My $2,000 Monthly Mistake
I remember the exact moment this became painfully clear. We were using a top-tier, expensive model to summarize our customer support tickets. The quality was great, but I watched our monthly AI bill climb at an alarming rate. It felt like a necessary cost of doing business, but something kept nagging at me to experiment. It was a knot in my stomach every time I reviewed the invoice.
So, we ran a simple head-to-head test. We pitted the expensive model’s summaries against those from a smaller, much cheaper alternative. The result was a genuine surprise. The cheaper model was 95% as effective for this specific task, but it cost a tiny fraction of the price. The switch was a complete no-brainer.
That single decision to compare and switch models saved us over $2,000 per month. It was a powerful, tangible lesson in the real-world impact of model selection. This wasn't about finding a "worse" model; it was about finding the right-sized tool for the job.
The Hidden Risks of Model Lock-In
Sticking with one model introduces risks that go far beyond just cost. When you rely on a single provider for all your AI needs, you're creating a dangerous dependency. A sudden price hike, an API outage, or even a subtle shift in the model's safety policies could derail your entire operation overnight (Schwartz et al., 2020). This isn't hype; it's a real operational threat.
Think about a few practical scenarios we've seen:
Marketing Content: A team using only a premium model for everything from ad copy to social media posts could easily see their costs spiral by 30-50%. A more balanced approach, using smaller models for simpler tasks, keeps the budget firmly in check. We now use this exact strategy.
Customer Experience: High latency from a huge, slow model can frustrate users and lead directly to churn. We learned that smaller, faster models can deliver the real-time responses customers actually expect, which directly impacts retention (Narayanan et al., 2021).
Operational Resilience: Diversifying our AI portfolio is just smart risk management for our tech stack. It protects our business from the volatility of leaning too heavily on a single provider.
Comparing AI models isn't just an academic exercise. It's an essential business process that protects your bottom line, improves your product, and keeps you agile. It’s about making data-backed decisions that give you a true competitive edge.
References
Narayanan, D., et al. (2021). Efficiently scaling transformer inference. Proceedings of the ACM International Conference on Measurement and Modeling of Computer Systems.
Schwartz, R., Dodge, J., Smith, N. A., & Etzioni, O. (2020). Green AI. Communications of the ACM, 63(12), 54–63.
The Founder's Framework for AI Model Comparison
When I first got serious about comparing AI models, I had a frustrating realization: the public benchmarks everyone obsesses over are mostly academic. They don’t tell you a thing about what a model will do for your cash flow, your product’s user experience, or your company's reputation. As a founder, I needed a practical framework that connected every single metric back to the business.
We don't just test models at Thareja AI; we live by a set of seven core metrics that translate directly into money, time, or risk. This is the exact framework we use to make every decision, ensuring we choose the right tool for the job, every time. It’s all about moving beyond theory and focusing on tangible business impact.
Here's a closer look at the seven metrics that actually matter.
Metric | What It Measures | Business Impact (Money, Time, Risk) |
|---|---|---|
Accuracy | The model's ability to produce correct, reliable, and contextually relevant outputs. | Time & Money: High accuracy reduces the need for human review and rework, saving countless hours and payroll costs. |
Latency | How quickly the model generates a response after receiving a prompt. | Money & Risk: Slow responses kill user engagement and can lead to customer churn. Every millisecond counts. |
Cost Per Task | The total expense to complete a specific job, including API calls and engineering overhead. | Money: A "cheap" model with high integration costs isn't cheap. This metric reveals the true cost of ownership. |
Safety & Bias | The model's tendency to produce harmful, biased, or inappropriate content. | Risk: A single unsafe output can trigger a PR nightmare, damage brand reputation, and create legal liabilities. |
Multimodal Capability | The ability to process and generate different data types like text, images, and audio. | Money & Time: Unlocks new product features and revenue streams without needing separate, specialized models. |
Fine-Tuning Support | How easily a model can be trained on your proprietary data to specialize its knowledge. | Money & Time: Creates a competitive moat and drastically improves performance on niche tasks, saving developer time. |
Hallucination Rate | How often the model confidently invents facts or presents false information as truth. | Risk: High hallucination rates erode user trust and can lead to disastrously wrong business decisions. |
These aren't just technical details; they are the pillars of a smart AI strategy. Each one has a direct and measurable effect on your bottom line.
Accuracy and Hallucination Rate
Accuracy isn't about getting a perfect score on some abstract test; it's about reliability. For us, the real question is, "Does the model produce outputs we can trust without constant human supervision?" An inaccurate model creates rework, which is a direct, painful drain on both time and money.
Closely tied to this is the hallucination rate—or, more simply, how often a model confidently makes things up. A model that hallucinates even 5% of the time can create enormous business risk, from providing incorrect financial data to generating outright false marketing claims (Ji et al., 2023). We measure this relentlessly by running models against a set of questions with known answers and tracking every single error.
Cost Per Task and Latency
Cost is so much more than the sticker price per million tokens. We always calculate the Total Cost per Task, a figure that includes the API price plus the engineering time spent on integration and maintenance. A "cheaper" model that demands 20 extra hours of your best developer's time isn't cheap at all.
Latency, or speed, is a critical, often underestimated, user experience metric. A two-second delay in a chatbot response might not sound like much, but it can be the difference between a happy customer and a lost one. For any real-time application, we aim for a response time under 500 milliseconds. Anything slower introduces a perceptible lag that just kills engagement (Akamai, 2017).
As a founder, I view latency as a direct reflection of our respect for the user's time. A fast, responsive product feels professional and builds trust, while a slow one feels broken and erodes it. I felt this frustration myself as a user of other products, and I refuse to build that into my own.
Safety, Bias, and Fine-Tuning
Safety and bias aren't just fuzzy ethical considerations; they represent massive brand risks. A model that generates biased or unsafe content can do irreparable damage to your reputation in a single afternoon. We test for this by hammering models with specific red-teaming prompts designed to expose these flaws before they ever see the light of day.
Fine-tuning support is our measure of how easily we can adapt a model to our specific domain and tone of voice. A model that supports easy fine-tuning can become a powerful, proprietary asset. Poor support means you’re stuck with a generic tool that will never fully understand your business context.
Finally, we look at multimodal capability—the ability to understand and generate text, images, and other data types. This isn't just a cool feature; it's crucial for building the next generation of products that go beyond simple text chat.
This framework isn't just for us; it’s a necessary lens for any business serious about building with AI. You quickly learn that no single provider is the best at everything. Enterprise adoption data shows a clear multi-vendor reality where teams constantly juggle different models. For instance, while Anthropic’s Claude recently captured 32% of the enterprise market, a massive 69% of organizations still use Google's models and 55% use OpenAI, proving that businesses mix and match to leverage specific strengths (discover the full LLM adoption statistics on Typeform).
The takeaway is simple: stop looking for one model to rule them all. Instead, build a mental model of a specialist's toolkit. Your goal is to deeply understand the strengths and weaknesses of each tool so you can pick the perfect one for every single task, optimizing for real-world business results, not just academic benchmarks (Kaplan et al., 2020). This is the very core of an effective AI strategy.
Putting AI Models to the Test in the Real World
Benchmarks and academic papers are a great starting point, but they don't tell the whole story. To really figure out which AI model will work for your business, we have to pit them against each other on the messy, unpredictable tasks our team tackles every single day. Abstract numbers on a chart just can't capture the subtle differences in tone, quality, and cost—the very things that directly impact your bottom line.
This is where the rubber meets the road. I'm going to walk you through a few practical comparisons drawn from my own experience building our company. We'll focus on what truly matters to founders: the money, time, and risk behind every choice.
This graphic really captures the balancing act we face when we compare AI models across the essential metrics of cost, speed, and risk.
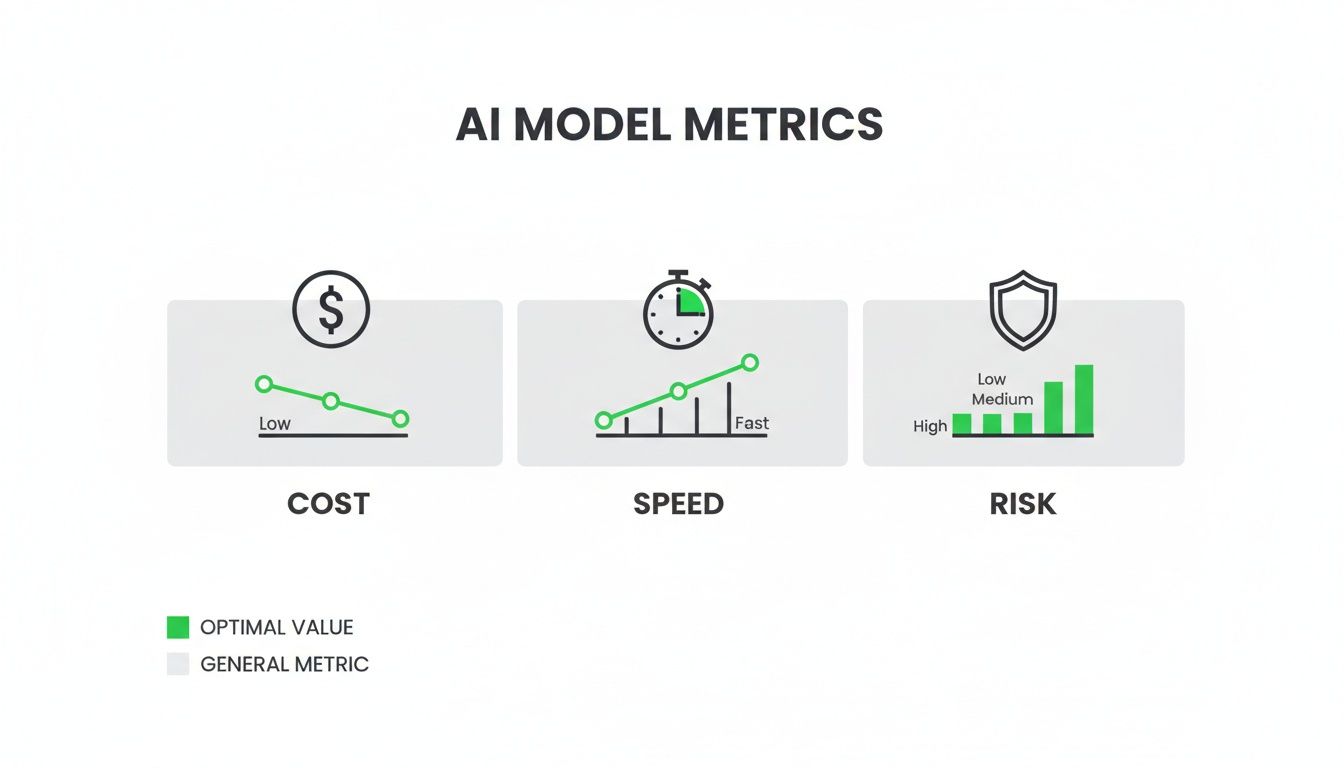
It’s a perfect visual reminder that the "best" model is rarely the most powerful or the fastest one. It’s the one that hits that sweet spot for what you need to accomplish right now.
Use Case 1: Summarizing a Dense Business Report
Picture this: It's 8 PM on a Sunday. A 50-page industry report just landed in my inbox, and I need the key insights for a 9 AM board meeting. The pressure is on. This isn't just about getting a summary; it's about pulling out mission-critical intelligence without missing a detail that could make or break a deal. I've been in this exact spot.
We ran this scenario, putting a premium model like Claude 3 Opus head-to-head with a more budget-friendly option like Mistral Large.
Claude 3 Opus: The summary was exceptional. It was nuanced, detailed, and even picked up on subtle market trends and competitor weak spots. The cost to process the hefty document was about $0.75.
Mistral Large: It delivered a solid, actionable summary that covered roughly 90% of the crucial points. While it missed some of the finer details, it was more than enough to get the job done for the meeting. The cost? A much more palatable $0.20.
For that high-stakes board presentation, the extra depth from Opus might justify the 3.75x cost. But for weekly internal updates? Mistral gives us almost all the value for a fraction of the price, saving a serious amount of cash over time.
This is a perfect example of why a one-size-fits-all strategy just doesn't work. The right choice is always about context and the financial stakes of the task. For more founder-focused insights, you can always check out our articles at https://www.thareja.ai/blog.
Use Case 2: Generating Python Code for Data Visualization
Let’s switch gears and look at it from a developer’s perspective. It’s the end of a sprint, and a product manager desperately needs a quick Python script to visualize some user data. You need code that works now—it doesn’t have to be a masterpiece. We've all been there.
We tested GPT-4o, renowned for its coding prowess, against a specialized model like DeepSeek Coder.
GPT-4o: It produced beautiful, well-commented Python code that ran perfectly on the first try. It was textbook stuff. Latency was around 3 seconds, and the cost was moderate.
DeepSeek Coder: This model spat out functional code that was a bit less elegant but achieved the exact same result. It needed one tiny tweak but was easily 80% as good for this specific job. The kicker? It cost only 20% of GPT-4o and was a touch faster.
For routine scripts or getting a first draft out the door, the specialized, cheaper model is a no-brainer. Those small savings on hundreds of similar tasks can add up to thousands of dollars in your development budget. For a deeper dive, this piece on comparing AI software development copilots is a fantastic resource for understanding which tools shine in different coding environments.
Use Case 3: Creating a Campaign-Winning Marketing Image
Imagine our marketing team launching a massive new campaign. A lot is riding on this. The right image could skyrocket conversions. The prompt is specific: "A vibrant, photorealistic image of a diverse team of young entrepreneurs collaborating around a holographic interface in a modern, sunlit office."
We put DALL-E 3 up against a faster, open-source alternative like Stable Diffusion.
DALL-E 3: The result was stunning. It was a highly detailed image that perfectly captured the creative vision of the prompt, nailing the nuances of "vibrant" and "photorealistic."
Stable Diffusion: It produced a good image, but getting it to the same quality level required more prompt engineering and a bit of manual cleanup. It was faster and cheaper per image, but it also demanded more human intervention to get it just right.
In this case, the trade-off isn't just about cost—it's about brand perception and creative impact. For a high-stakes campaign ad, the superior quality from DALL-E 3 is absolutely worth the premium. For internal slides or blog illustrations? Stable Diffusion is a fantastic and economical choice.
The real takeaway from these scenarios is that there’s no single "best" AI model. The smartest play is to build a versatile toolkit of models and cultivate an intuition for which one is the right tool for the job. Adopting this portfolio approach is how you truly optimize for cost, speed, and quality, turning AI from a cool experiment into a powerful competitive advantage.
AI Model Performance Snapshot for Key Business Tasks
To make this even more practical, here’s a quick-glance table showing which types of models tend to excel at common business tasks. Think of this as a starting point for your own experiments.
Task | Best for Quality (GPT-4o, Claude 3 Opus) | Best for Speed (Gemini 1.5 Flash, Llama 3 8B) | Best for Cost-Efficiency (Mistral 7B, DeepSeek Coder) |
|---|---|---|---|
Summarization | Excels at extracting nuance and context from dense, complex documents where every detail matters. | Ideal for quickly digesting internal emails, meeting notes, or daily news briefings. | A workhorse for processing high volumes of standard documents, like support tickets or customer feedback. |
Code Generation | Best for producing clean, production-ready code for complex logic or mission-critical applications. | Great for autocompleting snippets, generating boilerplate code, and rapid prototyping. | Perfect for writing simple scripts, unit tests, or converting code between languages at a low cost. |
Image Generation | Creates polished, brand-aligned visuals for major marketing campaigns and public-facing assets. | Quickly generates concepts, storyboards, and visual ideas for internal review. | Excellent for creating large batches of blog post images, social media graphics, or presentation aids. |
Retrieval | Provides highly accurate, context-aware answers from large knowledge bases for customer-facing chatbots. | Powers internal search tools and Q&A bots where speed is more critical than perfect accuracy. | A cost-effective solution for basic document search and retrieval within a controlled dataset. |
This table isn't about declaring winners, but about guiding your strategy. The ultimate goal is to match the right tool to the right task, creating a system that’s not just powerful, but also incredibly efficient.
Building Your AI Decision Matrix
The raw power of a model is one thing, but what really matters is whether it's the right tool for the job you have right now. The truth is, the single "best" AI model doesn't exist. The "right" model, however, absolutely does. This is where we stop talking about abstract benchmarks and start making concrete, confident decisions.
At our startup, we traded ad-hoc choices for a simple but powerful tool: the decision matrix. It’s not some ridiculously complex spreadsheet. Instead, it’s a straightforward way to weigh what matters most for a specific task and the person doing it. I quickly realized that what I care about as a founder—cost-efficiency and long-term stability—is often worlds away from what my team needs to get their work done. This matrix gives us a shared language to make smart, consistent choices together.
The Founder's View: Cost and Risk First
As a founder, every dollar and every decision feels heavy. My version of the decision matrix is ruthlessly focused on the bottom line and keeping the company on solid ground. I learned the hard way that chasing the absolute highest quality output for every little task is a fantastic way to burn through your runway.
My matrix zeroes in on these factors above all else:
Cost Per Task: What is the absolute cheapest model that can get this job done to a "good enough" standard?
Long-Term Reliability: Will this model's provider still be around in two years? What are the odds of a sudden price hike or API change that breaks our entire workflow? (Schwartz et al., 2020)
Scalability: Can we crank this up to process 10,000 tasks without hitting insane rate limits or getting a shocking bill?
This perspective forces tough, but necessary, calls. When we're picking models for internal data processing, for example, I'll always push for a model that's slightly less accurate but 50% cheaper. Those cumulative savings across thousands of runs go directly back into our runway.
The Marketer's Matrix: Creativity and Safety
Our marketing team operates in a completely different reality. For them, a single off-brand or unsafe output can cause far more damage than a high API bill. Their matrix is all about creative quality and protecting our brand. It was a genuine lightbulb moment when I saw how they weighed their options.
A marketer’s matrix looks something like this:
Creative Quality: How well does the model actually capture our brand voice or nail our visual style?
Brand Safety: What is the chance it will generate something inappropriate or offensive? This is completely non-negotiable.
Speed to Market: How fast can we get high-quality assets out the door for a campaign that’s moving at the speed of light?
I saw this in action when our team chose DALL-E 3 for a high-stakes ad campaign. It was more expensive, but its knack for following a complex creative brief was just in another league. For everyday blog post illustrations, though, they happily use a faster, cheaper alternative. The matrix empowers them to make that call without my micromanagement.
The AI market is also exploding globally. In 2023, North America held 42.1% of the generative AI market share, but the Asia-Pacific region is set to grow fastest with a projected 45.9% CAGR. This global shift highlights why you need tools that aren't geographically limited, allowing teams everywhere to compare AI models and get their hands on the best tech. If you're interested in these trends, you can explore the full report on generative AI market growth.
The Developer's Priorities: Speed and Reliability
Finally, our developers have their own lens. They’re the ones in the trenches, building the products our customers depend on. For them, performance and predictability are everything. A slow or unreliable API directly translates to a terrible user experience and late-night emergency fixes.
Their matrix is clear and technical:
Latency: Is the response time snappy enough for a real-time application?
API Reliability: What’s the provider’s uptime record? How good is their documentation, really? (Narayanan et al., 2021)
Integration Cost: How many engineering hours are we going to sink into implementing and maintaining this thing?
This framework isn't about setting rigid rules. It's about empowering each part of your team to make informed, justifiable decisions that line up with their own goals. The mental model is simple: define what success looks like for the task, then pick the model that gets you there most efficiently. This system turns AI adoption from a string of educated guesses into a repeatable, scalable strategy.
How We Built a Smarter Way to Compare AI Models
Let's be honest: manually testing and comparing AI models is a painful, slow-motion nightmare. It just doesn't scale. Early on, we were living that nightmare. Every hour we spent setting up another side-by-side test was an hour we weren't building our actual product. I felt that pain personally, and I knew there had to be a better way.
That deep-seated frustration was the spark that led us to build comparison and routing tools right into our platform, Thareja AI. This wasn't about tacking on another feature. It was about solving a real, nagging business problem we faced every single day. The result is our 'Automatic Mode,' and I want to give you a look under the hood at how it works.
Intelligent Routing in Action
Instead of making you play a guessing game, our system figures out what you're trying to do. It analyzes your prompt and automatically sends it to the best model for that specific task, always juggling cost, speed, and quality.
For instance, say a user needs to summarize a massive, 100-page financial report. The system immediately gets that this requires a huge context window and top-tier accuracy, so it will probably tap a workhorse like Claude 3 Opus.
But a second later, that same user might ask to brainstorm five snappy blog post headlines. The system sees this as a quick, creative job with low complexity. It instantly fires that prompt off to a faster, much cheaper model like Llama 3 8B. This all happens behind the scenes, without you even noticing.
The impact on the bottom line is huge. Our internal data and early client results show this intelligent routing slashes costs by 30-50% and completely wipes out the hours previously wasted on manual model picking.
Making Real-Time Comparisons Effortless
We didn't just want to automate things; we wanted to give people the power to see different model "opinions" side-by-side. So, we built an instant comparison feature directly into our chat interface. With one click, you can run your prompt across multiple models and watch their answers pop up right next to each other.
This isn't just a neat trick. It’s an incredibly useful way to find the perfect phrasing, check facts from different sources, or just pick the tone that feels right for you. It puts the control to compare AI models right at your fingertips, friction-free.
The AI field is moving at lightning speed, especially with the push-and-pull between giant large language models (LLMs) and their smaller, more efficient cousins (SLMs). The big models demand a ton of resources, but the nimble SLMs are hitting a sweet spot of performance and cost. For anyone building a business, having a platform that can handle both is no longer a luxury—it's essential. Getting locked into a single model is a recipe for falling behind.
Our automated approach isn't just a sales pitch; it's a look at where applied AI is headed. We believe smart systems should handle the model selection for you, so you can focus on what you're actually trying to accomplish. This whole idea came from our own struggles as founders, which you can read more about at https://www.thareja.ai/about.
If there's one thing to take away, it's this: the best way to compare AI models is to have a system do it for you, intelligently and continuously. The end goal should be to make model selection an invisible, optimized process that saves you time and money without you ever having to think about it.
Adopting a Multi-Model Mindset for Your Business
The single most important lesson you can take away from any AI model comparison is this: you have to change your thinking. Stop searching for one "perfect" AI and start thinking like a conductor leading an orchestra. Each model is an instrument, and your job is to know when to call on the violin for a delicate melody and when to bring in the brass section for a powerful blast.
I call this mental shift "The Portfolio Approach." When you see AI models as a portfolio of specialized tools instead of a single, all-purpose hammer, you unlock real productivity and innovation. I remember when we first started; I was obsessed with finding the 'best' model. That obsession cost us money and time. The shift from chasing a silver bullet to building a strategic toolkit was liberating and, frankly, much more profitable.
The Power of a Portfolio
Embracing this approach isn't just a theoretical exercise—it’s a core strategy that has a direct, measurable impact on your business.
Risk Mitigation: You're no longer hostage to a single vendor's pricing whims, performance issues, or outages. Diversifying your models builds resilience right into your tech stack.
Cost Optimization: You can always use the most economical tool that gets the job done well. This simple principle has saved us an estimated 30% on AI operational costs, just by avoiding overkill on simple tasks.
Enhanced Quality: You get to use the absolute best-in-class model for every specific job, whether it's creative writing or complex code generation. The quality of your final output improves dramatically.
This strategy is all about making thousands of slightly better decisions. Over time, those small optimizations in cost, speed, and quality compound into a massive competitive advantage. It's the difference between merely using AI and truly mastering it.
For anyone looking to take this a step further, diving into topics like powerful ensemble methods in machine learning can give you a more advanced, technical framework for combining model outputs to achieve even better results.
This mindset is your real takeaway. The next time you write a prompt, don't just ask, "Is this a good response?" Ask the question that actually drives growth: "Could another model have done this faster, cheaper, or better?" That one question is the key to building a smarter, more resilient AI strategy.
Frequently Asked Questions About Comparing AI Models
As a founder, I find myself answering the same handful of questions whenever a team starts seriously comparing AI models. That initial phase can feel like navigating a maze in the dark, but the right perspective can cut through the noise and give you a clear path forward.
Here are the questions I hear most often, along with the straight-up, practical answers I always give.
Which AI Model Is the Best Overall?
This is always the first question, and my answer never changes: there is no single 'best' model. Believing there's a one-size-fits-all solution is the biggest trap you can fall into. The "right" model is always the one that’s best for the specific job you need done.
If I’m working on high-stakes creative writing or something that requires deep, nuanced reasoning, I'll probably reach for a powerhouse like GPT-4o or Claude 3 Opus. But if I just need some quick code snippets, a specialized model like DeepSeek Coder is often the smarter, faster choice. For quick and cheap answers to simple questions? Llama 3 8B is brilliant.
The most critical mental shift is to stop searching for one winner and start building a versatile toolkit of models you can deploy strategically.
How Much Money Can I Really Save?
The savings aren't just theoretical; they are real and they are significant. Looking at our own internal data and what we see with client pilots, businesses can realistically expect to cut their AI operational costs by 30% to 50%. I’ve seen it happen time and time again.
Think about it: using an expensive, top-tier model to simply reformat a block of text might cost 10-20 times more than using a smaller, faster model that gives you the exact same result. It feels like a minor tweak, but when you're making thousands of API calls, those tiny optimizations compound into thousands of dollars back in your pocket every single month. That's real cash flow you can use to grow your business (Kaplan et al., 2020).
Is It Difficult to Switch Between Different AI Models?
Traditionally, it was a massive headache. If you wanted to integrate APIs from OpenAI, Anthropic, and Google, you were signing up for a ton of developer hours and a maintenance nightmare. Each platform has its own documentation, authentication quirks, and data structures. It’s a mess.
This is the exact problem we built Thareja AI to solve. It was born directly from our own frustration with this process. Our platform brings over 50 models together under a single, unified API. You can switch between them with a single click in a chat interface or by changing just one line of code. We take care of all the backend complexity for you.
If you have more specific questions about how to get started, our team is always happy to help you find the answers you need. Just reach out to our team by visiting https://www.thareja.ai/contact. We’re passionate about helping other founders navigate this space because we’ve been in the trenches ourselves. The goal is to let you focus on getting the best results, not on fighting with APIs.
Ready to stop guessing and start making data-driven AI decisions? Thareja AI unifies over 50 top models in a single, intuitive platform. Compare, route, and optimize your AI usage to save up to 50% on costs. Start your free trial today.
